AI-driven proactive autoscaling - a theoretical approach
This article is the condensed version of my bachelor’s thesis, which I completed in 2025 as part of my studies. In it, I examined which AI approaches/algorithms are best suited to proactively scale cloud resources. As indicated in the title, this article approaches the topic from a theoretical and scientific perspective. The distinction is important, as the follow-up article will focus on the practical application and highlight the significant differences between the two approaches. Since this is a shortened version of my thesis, it goes without saying that only the essential sources and information are presented. Anyone who would like to delve deeper or read the full thesis is welcome to get in touch with me.
1 Initial situation and research question
The use of artificial intelligence (AI) for automatic scaling of cloud resources is becoming increasingly important in modern IT infrastructure. Classic, reactive scaling systems are reaching their limits: they only adjust resources once a utilization threshold has already been exceeded — an approach that is particularly problematic for time-critical systems with short ramp-up times. The aim of this paper is therefore to examine which AI algorithms are best suited for proactive scaling — that is, scaling that recognizes and responds to load peaks in advance.
The central research question is:
How effective and economically viable are different AI algorithms in the context of an enterprise system, and which approach is best suited for proactive load adaptation in a production-like environment?
The methodological approach of this paper is deliberately theoretical and scientific in nature: all results are based on a systematic literature review as well as controlled experimental testing using historical production data in accordance with established scientific quality criteria.
2 Theoretical foundations
Cloud computing and autoscaling
Cloud computing enables the provision of IT resources over the internet according to demand. A central feature of modern cloud environments is elasticity — that is, the ability to dynamically adapt resources to current requirements. Autoscaling refers to this process of automatic resource adjustment. A basic distinction is made between reactive (downstream) and proactive (predictive) scaling. Since starting up new computing units (so-called pods) takes time, while the load arises immediately, a proactive approach is necessary.
Artificial intelligence and learning paradigms
For the problem at hand, three learning paradigms are relevant:
- Machine Learning (ML): Detects patterns in data in order to make predictions. It is well suited for structured data with linear patterns, but it does not provide its own decision logic for scaling actions.
- Deep Learning (DL): A specialization of ML based on multilayer neural networks. It can also process unstructured, non-linear data, but is computationally intensive and difficult to interpret.
- Reinforcement Learning (RL): An agent learns through repeated interaction with an environment by being rewarded for good decisions and penalized for bad ones. What is special here is that RL does not require pre-labeled target data and makes decisions autonomously — a key requirement for autonomous autoscaling (cf. Sutton 2015).
An overarching concept that connects all three paradigms is Time Series Forecasting (TSF): predicting future values based on historical time-series data. Methodologically, the entire paper is situated within this framework.
3 Methodological approach: two-stage literature analysis
In order to identify the most promising AI approaches for the autoscaling problem from the large number available, a two-stage quantitative literature review was conducted. The underlying assumption: the density of scientific publications on an algorithm is a valid indicator of its practical relevance and robustness, since heavily published methods are evaluated more often and are therefore more widely accepted.
Stage 1 – Comparing learning paradigms: On the platforms Google Scholar, Semantic Scholar, IEEE Xplore, and arXiv, a combined Boolean and keyword search was carried out for each learning paradigm (Supervised, Unsupervised, Deep Learning, Reinforcement Learning) in the context of autoscaling. The result (cf. Fig. 1) clearly shows that Reinforcement Learning and Deep Learning dominate the research landscape, while Supervised and Unsupervised Learning play a subordinate role.
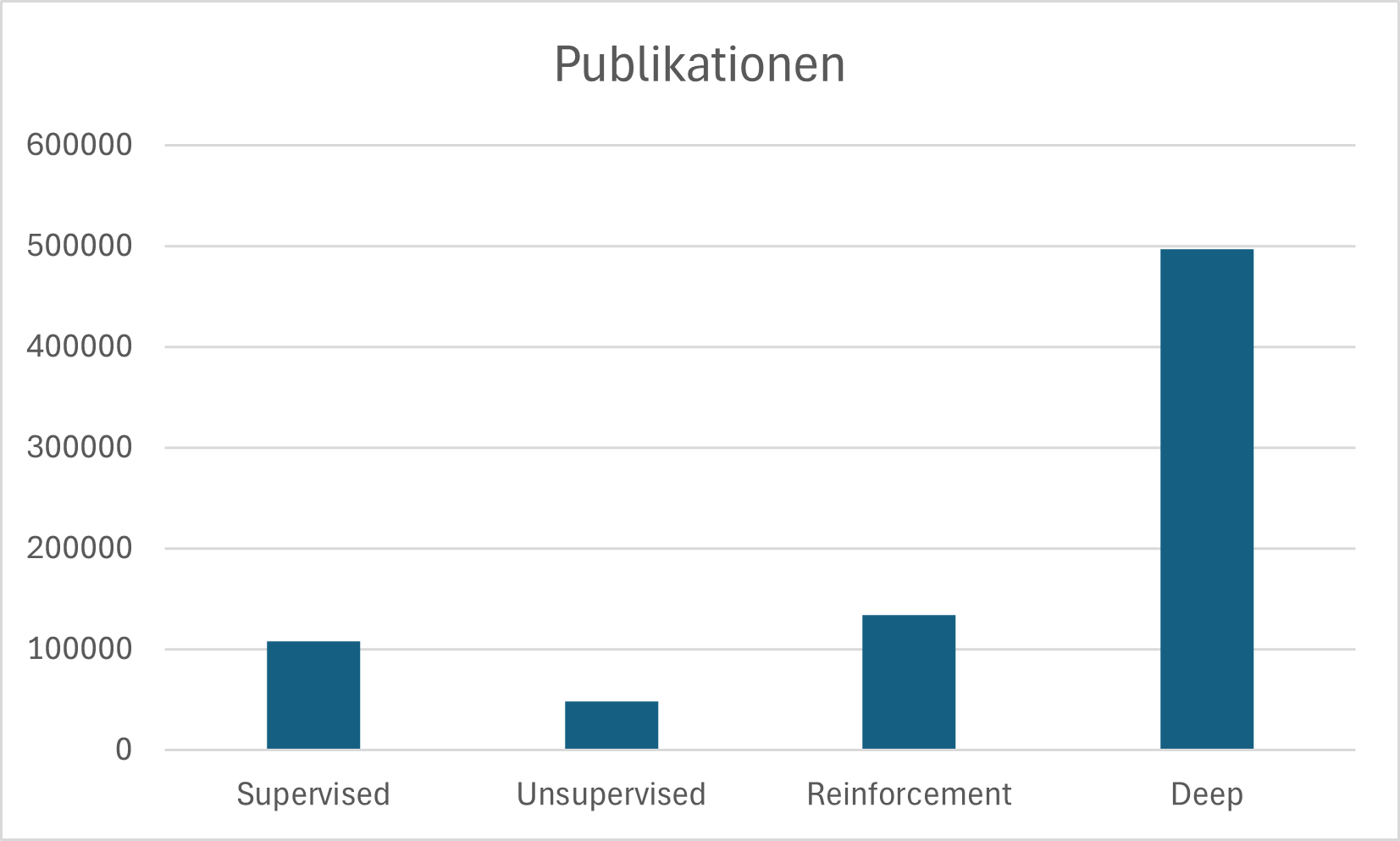
Despite its high publication count, Deep Learning is ruled out as the primary approach: models such as LSTM can certainly produce precise load forecasts (Bi-LSTM outperforms ARIMA in accuracy by about 7% and is up to 600 times faster, cf. Siami-Namini 2018), but they do not include integrated decision logic for autonomous scaling. They would require additional control mechanisms, which would have exceeded the scope of this paper. Reinforcement Learning, on the other hand, combines both requirements: training without labeled data and autonomous decision-making. It is therefore chosen as the primary paradigm for this paper.
Stage 2 – Comparing RL algorithms: In a second step, the same search methodology was applied to specific RL algorithms (cf. Fig. 2). First, all algorithms with very low publication density were excluded (including World Models, AlphaZero, A2C, SAC). The remaining, frequently published algorithms were: Policy Gradient, DDPG, TRPO, DQN, and PPO.
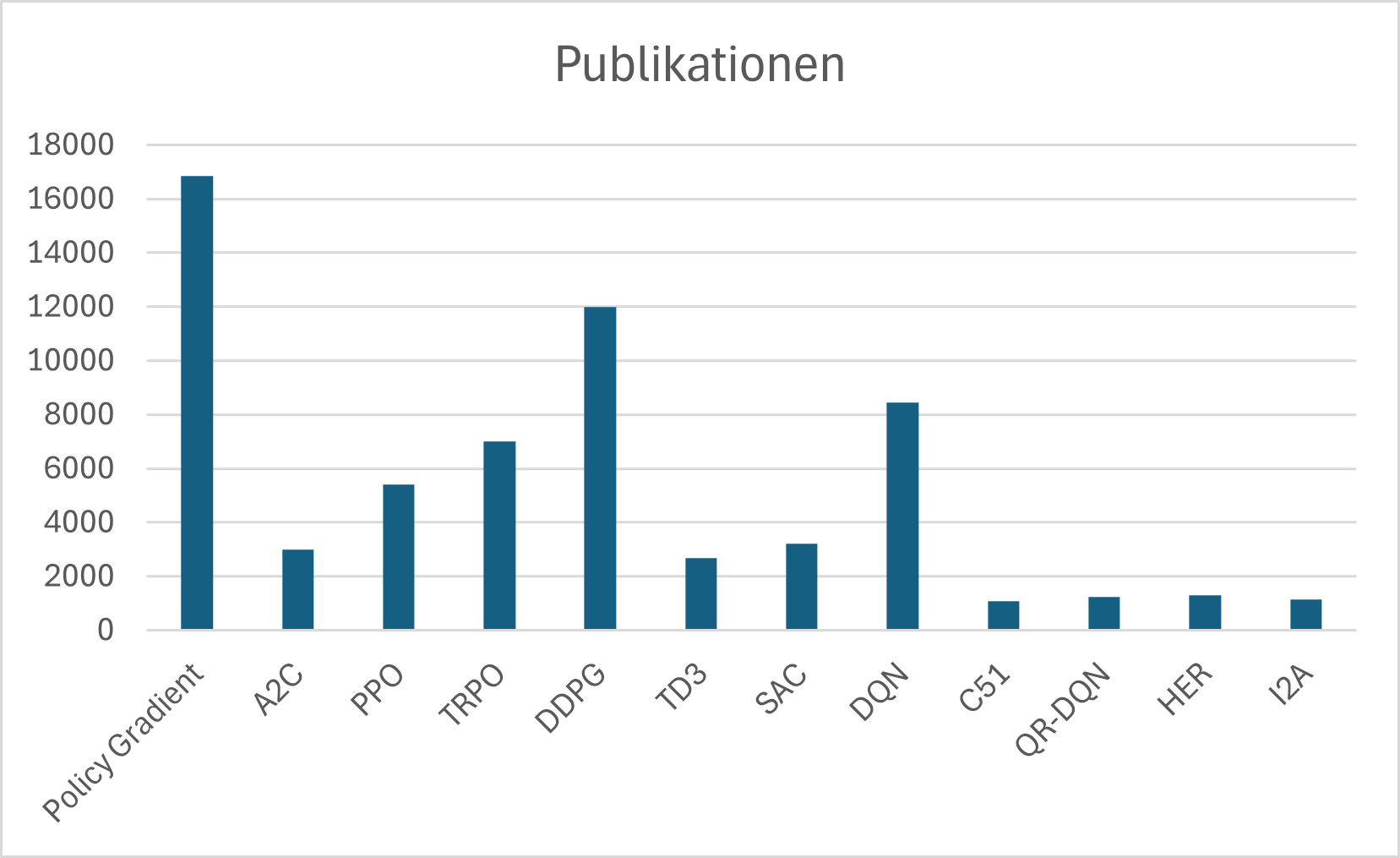
Policy Gradient is excluded on the basis of a qualitative assessment: the algorithm is considered outdated, suffers from high gradient variance, and appears primarily as a reference point in studies (cf. Schulman 2017). TRPO is set aside in favor of PPO. Since PPO, despite being theoretically less exact, delivers comparable or better results in practice with significantly simpler implementation.
This leaves PPO, DQN, and DDPG for further examination.
4 Description of the three algorithms
PPO (Proximal Policy Optimization) belongs to the class of policy-based RL methods. It incrementally learns a decision strategy (policy) by ensuring that updates do not become too drastic — controlled by a clipped objective. This prevents unstable learning behavior. PPO is regarded as stable, resource-efficient, and highly scalable (cf. Schulman 2017).
DQN (Deep Q-Network) is a value-based RL approach in which a neural network learns how good a particular action is in a given state (Q-function). Two core techniques stabilize the learning process: experience replay (random reuse of past experiences) and a separate target network (which prevents the model from having to adapt to constantly changing target values). DQN is particularly well suited to discrete decision spaces (cf. Mnih 2013).
DDPG (Deep Deterministic Policy Gradient) combines DQN with the Deterministic Policy Gradient approach. It works with two neural networks: an actor, which proposes actions, and a critic, which evaluates them. Crucially, unlike DQN, DDPG also allows continuous actions — for example, scaling by exactly 1.7 units instead of being limited to integer values (cf. Lillicrap 2016).
5 Experimental testing
Data basis and preprocessing
A real-world dataset from a production environment was available for training (~50,000 data points) with the following metrics: number of requests, RAM utilization, and service response time, supplemented by timestamps. The test dataset (~10,000 data points) covered a separate, later time period.
Since there were no explicit target values for the optimal number of pods (the target system currently operates at maximum configuration which is needed), so-called pseudo-labels were generated: based on the observation that one pod can handle an average of ~900 requests, the required number of pods was heuristically derived for each case. These pseudo-labels were used during pretraining as target values in order to initialize the RL agent with a sensible starting strategy.
Test design
All three algorithms were tested under identical conditions: same network architecture (two hidden layers, 128 neurons each), same training data, same reward function. Five runs with different random initializations (seeds) were carried out for each configuration in order to reduce random fluctuations. In total, three iterative test configurations were performed, with specific hyperparameters adjusted in each case.
Evaluation metrics
| Metric | Description |
|---|---|
| Accuracy | Share of exactly correct predictions |
| MAE (Mean Absolute Error) | Average deviation from the target value |
| ±1 tolerance | Predictions that deviate by at most 1 pod from the target value |
| Over-/underprovisioning | Share of resources provisioned too much / too little |
Particularly critical is underprovisioning: if too few resources are provided, this can lead to system delays or outages.
6 Results
The third and final test run delivered the best results across all models so far, because algorithm-specific adjustments were made iteratively: for PPO, gradient clipping and a reduced learning rate were introduced; for DQN, Double DQN was activated and the replay buffer was enlarged; for DDPG, a warm-up phase and stochastic exploration noise were added.
The following table shows the averaged results across five seeds in the third run:
| Metric | PPO | DQN | DDPG |
|---|---|---|---|
| Accuracy | ~8% | ~70% | ~78% |
| ±1 tolerance | ~25% | ~92% | ~97% |
| MAE | ~17% | ~2% | ~1% |
| Underprovisioning | ~58% | ~15% | ~13% |
| Overprovisioning | ~34% | ~16% | ~9% |
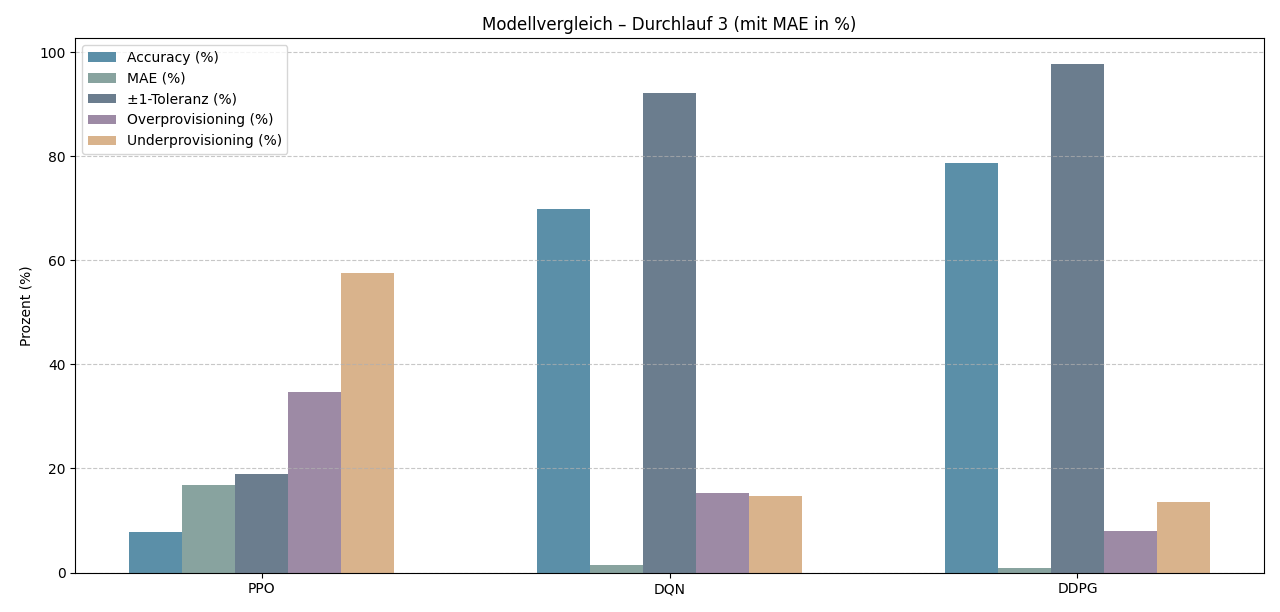
PPO showed, despite clear improvement over the first runs, a maximum accuracy of only around 8%, which was too low for productive use. In most cases, the decisions were far from the actual requirement.
DQN achieved solid results with around 70% accuracy and a ±1 tolerance of around 92%. This means that in almost all cases the prediction was either exactly correct or off by at most one unit.
DDPG delivered the strongest overall results: around 78% accuracy and a ±1 tolerance of ~97% — meaning that almost all decisions were correct or missed by only one pod. At the same time, DDPG showed the lowest underprovisioning, which is especially relevant for production-like use.
Notably, the ranking of the algorithms by test result (DDPG > DQN > PPO) exactly mirrors the order of publication frequency from the literature analysis — an indication that the chosen methodology for identifying algorithms is valid.
7 Economic perspective
In addition to prediction quality, the economic impact of this proactive approach was also considered. The target system previously operated with a fixed configuration of 12 pods at all times, regardless of the actual workload. By applying the best-performing algorithm (DDPG), the predicted pod counts were documented and averaged across the test period.
The analysis showed that the model requested around 8 pods on average instead of the fixed 12. This suggests a potential resource reduction of roughly one third, which translates to an estimated cost saving of around 30% for this initial model. These numbers clearly demonstrate that AI-based autoscaling can effectively reduce unnecessary overprovisioning.
However, this estimate should be interpreted with caution. A realistic assessment of actual cost savings must also take into account operational expenses, implementation effort, and ongoing development costs. While a comprehensive financial evaluation is still pending, the results prove that there is significant potential to reduce resource usage and lower infrastructure costs.
8 Conclusion and interpretation
The paper shows that Reinforcement Learning is fundamentally suitable for proactive cloud autoscaling, but requires considerable tuning effort. Even small parameter adjustments — such as reducing the learning rate or introducing a warm-up phase — had measurable effects on model performance.
Based on the theoretical-scientific approach of this paper, DQN and especially DDPG were identified as the most suitable algorithms. PPO proved insufficiently powerful for the specific problem of pod-accurate scaling prediction.
It should be noted, however, that the present results are theoretically grounded first attempts. All tests are based on historical data; real production conditions introduce additional complexity. The concept of pseudo-labels as a training basis is a heuristic approximation whose empirical validation is still pending. For a robust practical deployment, more extensive datasets, longer training periods, and validation under live conditions would be necessary — this is the subject of further work.
Note: For complete references, please contact the author. Key references: Sutton (2015) on RL fundamentals; Schulman (2017) on PPO; Mnih (2013) on DQN; Lillicrap (2016) on DDPG; Siami-Namini (2018) on LSTM vs. ARIMA.